Contents
- Intelligence vs. Cost
- Can It Survive the Agentic Era?
- Context Window
- Output Speed
- Multimodality
- Cost and Providers
- Summary
- Appendix: OpenRouter vs Direct Providers
- Update (March 2026): MiniMax-M2.7 vs Kimi K2.5 for Agentic Work
I have been thinking about running local or API-hosted open source models for a while now. The price point has become genuinely attractive, so I decided to zero in on a few contenders and compare them head-to-head. The five models I am looking at are GLM-5 (Zhipu AI), Kimi K2.5 (Moonshot AI), MiniMax-M2.5, Qwen3.5 397B A17B (Alibaba), and DeepSeek V3.2 (DeepSeek AI). All five are Chinese-lab models, which says something about where a lot of the open source momentum is right now.
Throughout this post, I only consider the thinking/reasoning variants of all models. Where data for a non-thinking variant is referenced for comparison purposes, it is explicitly noted as (non-thinking) in context. For Claude, both the non-thinking and the adaptive reasoning (max) variants share the same per-token price – the distinction matters for verbosity and total cost, not the rate itself.
This post is intentionally approximate and high-level. The numbers and charts come from Artificial Analysis, which tracks live benchmark results and pricing across hundreds of models and providers. For precise, up-to-date data and methodology, I recommend going there directly.
The short version: GLM-5 is the most well-rounded, Kimi K2.5 is the strongest pure coder, and DeepSeek V3.2 is the dark horse – competitive intelligence at a price that undercuts everything else by a wide margin. Let me go through each dimension.
Section 1: Intelligence vs. Cost
The first thing I checked was raw intelligence relative to price. Artificial Analysis has a great interactive chart for exactly this – they compute an “Intelligence Index” across a battery of benchmarks and plot it against token price, so you can see who is in the sweet spot.
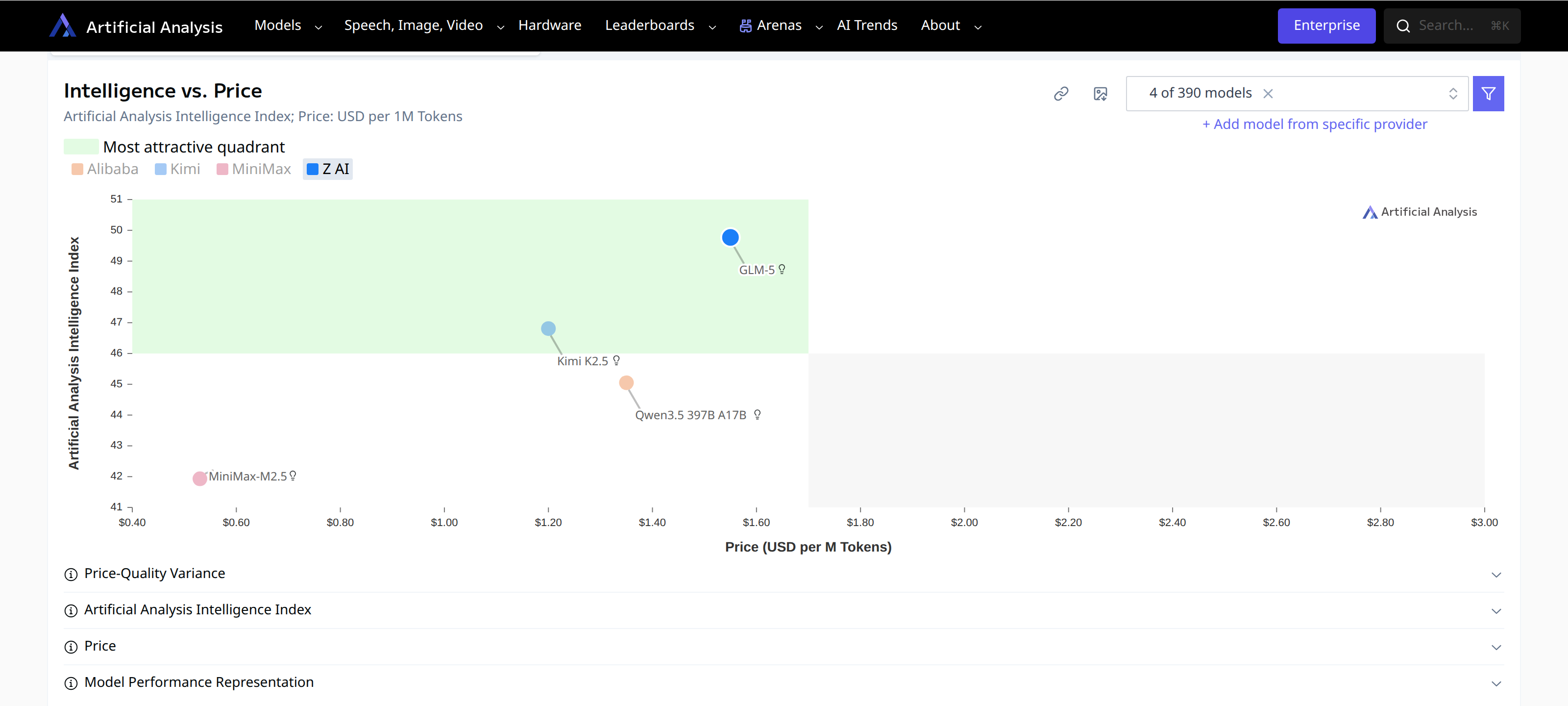 Intelligence Index vs. input/output token price. Higher and to the left is better. (Artificial Analysis)
Intelligence Index vs. input/output token price. Higher and to the left is better. (Artificial Analysis)
GLM-5 and Kimi K2.5 both sit in the upper portion of the chart – higher intelligence than MiniMax and Qwen at competitive prices. Both land close to the “most attractive quadrant” (high intelligence, low cost).
One thing worth noting: GLM-5 is a bit chatty. It tends to produce more output tokens to arrive at its answers. That drives its per-query cost up somewhat compared to Kimi K2.5, even if the per-token price looks similar. The chart below, which uses Artificial Analysis’s “cost to run the Intelligence Index” metric (i.e., total cost to complete their benchmark suite), makes that visible:
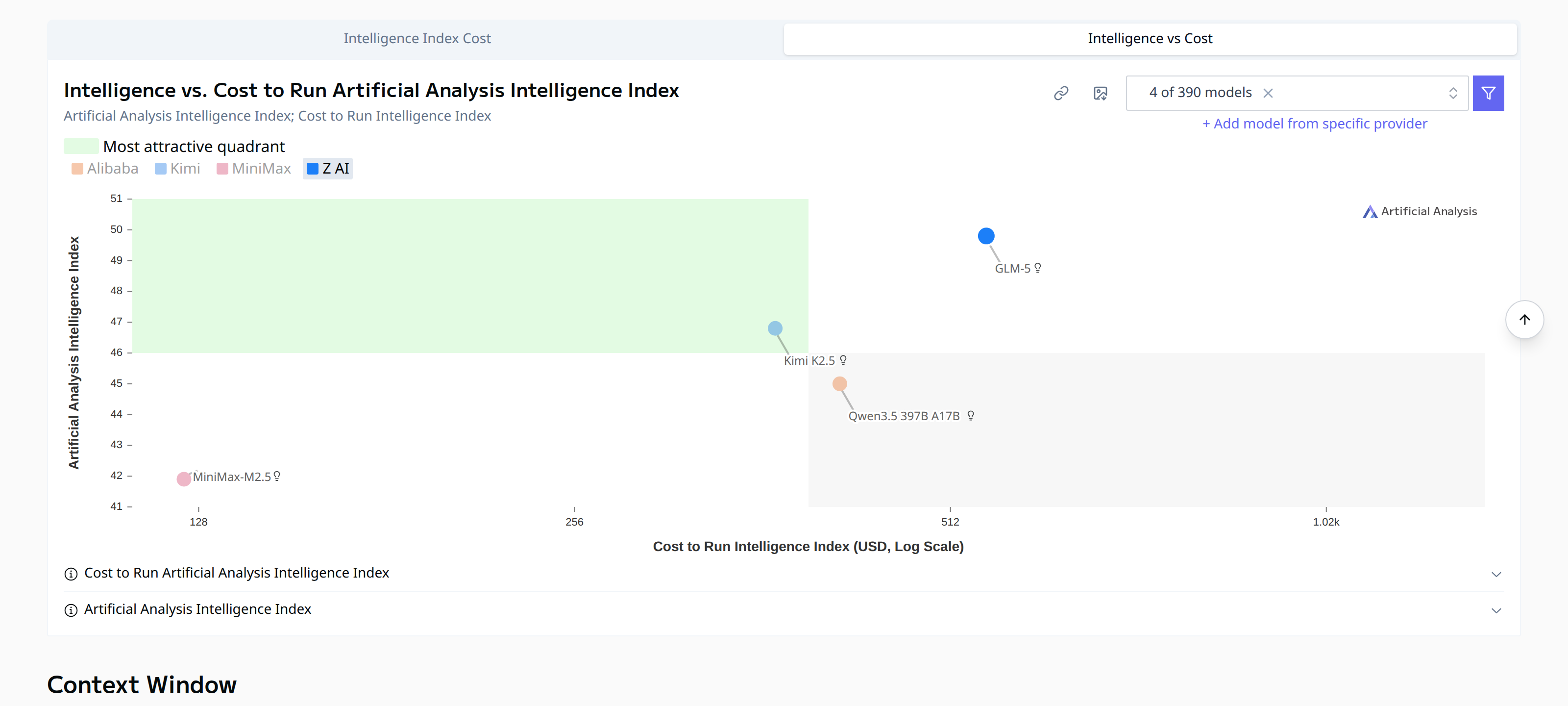 Intelligence vs. total cost to run the AI benchmark suite. GLM-5 is slightly more expensive to operate than Kimi K2.5 despite similar raw pricing. (Artificial Analysis)
Intelligence vs. total cost to run the AI benchmark suite. GLM-5 is slightly more expensive to operate than Kimi K2.5 despite similar raw pricing. (Artificial Analysis)
Kimi K2.5 comes out a bit cheaper in practice once you account for verbosity. So if cost efficiency is the primary driver, Kimi has a small edge. If you want the highest intelligence without worrying too much about token spend, GLM-5 is the pick.
Note on DeepSeek V3.2 (Reasoning): The charts above were generated before including DeepSeek in this comparison. DeepSeek V3.2 (Reasoning) scores 42 on the Artificial Analysis Intelligence Index – matching GLM-5 – while pricing at just $0.28/$0.42 per million input/output tokens. On the cost-vs-intelligence chart, it would sit far to the left of all other models at the same intelligence level, making it arguably the best value in this entire comparison. The caveats are a smaller 128k context window, text-only input, and slower native speed (though Fireworks brings it to 105 t/s).
For the exact methodology behind the Intelligence Index, see Artificial Analysis’s documentation.
Update: As of mid-March 2026, MiniMax-M2.7 has taken the lead among open-weight models with an Intelligence Index of 50, and Kimi K2.5 follows at 47. See Section 9 for the updated comparison.
Section 2: Can It Survive the Agentic Era?
Raw intelligence scores are one thing. What matters more for real workflows is whether a model can handle multi-step agentic tasks without going off the rails. I came across some benchmark results comparing these four models on exactly that.
First, the agentic benchmarks – GDPval-AA (real-world agentic task completion) and Terminal-Bench Hard (coding and terminal use under agentic conditions):
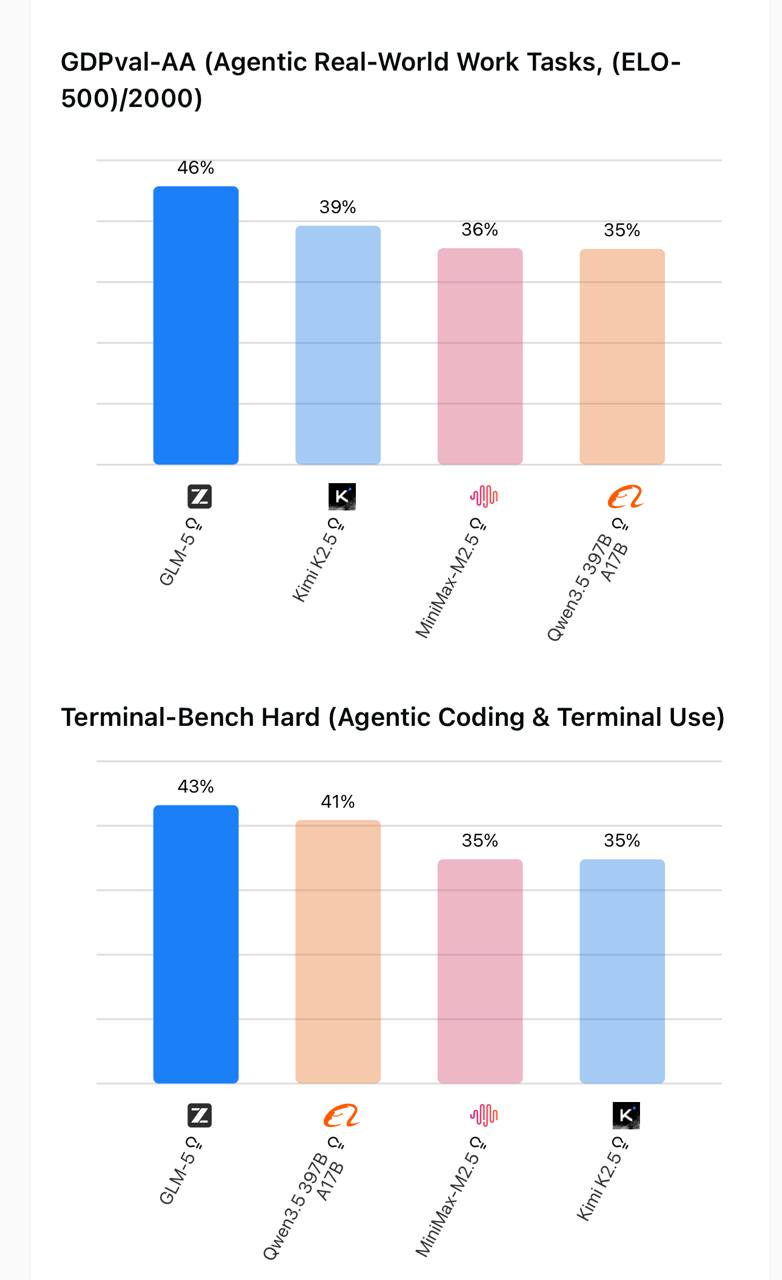 Left: GDPval-AA agentic real-world task scores. Right: Terminal-Bench Hard coding and terminal scores.
Left: GDPval-AA agentic real-world task scores. Right: Terminal-Bench Hard coding and terminal scores.
GLM-5 leads on GDPval-AA (46%) with a meaningful gap over Kimi K2.5 (39%). On Terminal-Bench Hard, GLM-5 still leads (43%) but Kimi K2.5 is close behind (41%). Both MiniMax and Qwen trail at 35-36% across both.
To put that in perspective, here is where these models land against the full field – including the proprietary frontier models everyone pays a premium for:
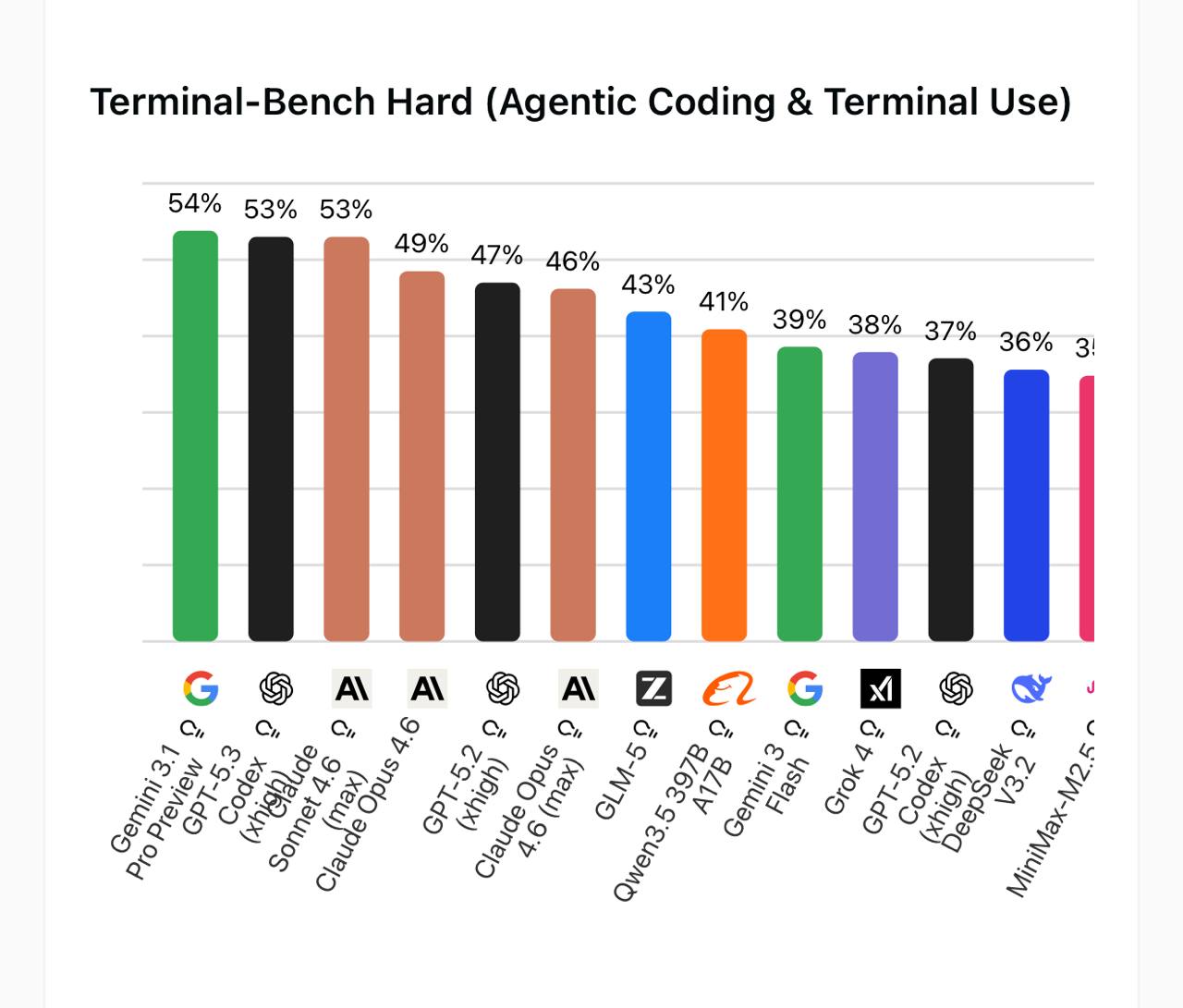 Terminal-Bench Hard: full leaderboard including proprietary models. GLM-5 at 43% sits just behind Claude Opus 4.6 max (46%) and ahead of several other frontier models.
Terminal-Bench Hard: full leaderboard including proprietary models. GLM-5 at 43% sits just behind Claude Opus 4.6 max (46%) and ahead of several other frontier models.
Gemini 3.1 Pro Preview, GPT-5.3, and Claude Sonnet 4.6 cluster at the top around 53-54%. GLM-5, an open-weight model you can run yourself, comes in at 43% – which means it nearly matches Claude Opus 4.6 max (46%), the agentic model that has had a lot of attention lately. That is a striking result for an open source model at a fraction of the API cost.
Then there is hallucination. For agentic work this is arguably the single most important metric – a model that confidently makes things up is worse than useless when it is acting autonomously on your behalf.
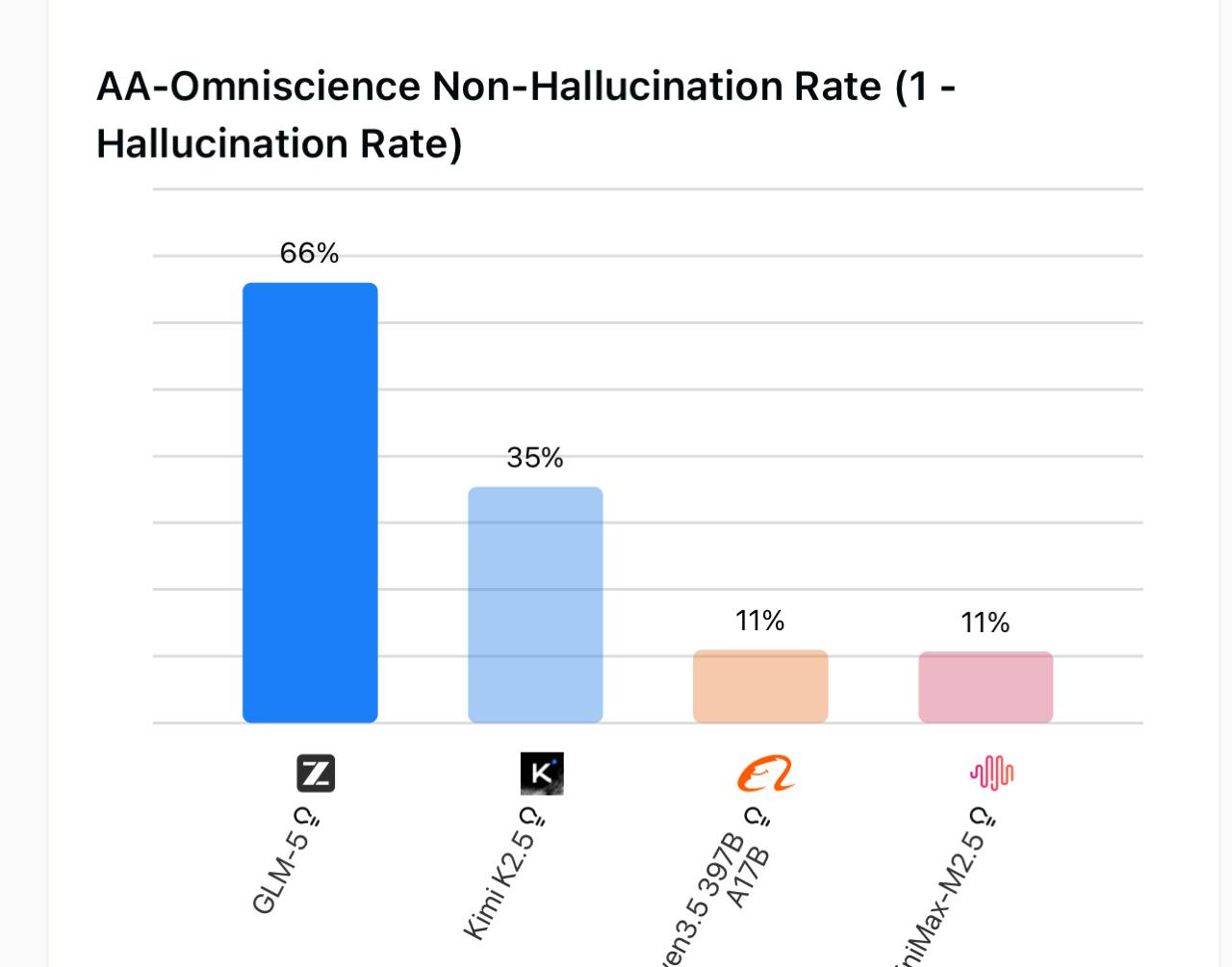 1 minus hallucination rate – higher is better. GLM-5 at 66% is nearly double second place.
1 minus hallucination rate – higher is better. GLM-5 at 66% is nearly double second place.
GLM-5 at 66% non-hallucination rate is striking. Kimi K2.5 comes in at 35%, and both MiniMax and Qwen fall off to around 11%. That is not a close race. For any autonomous agent work, GLM-5’s factual reliability is a serious advantage.
Where Kimi K2.5 fights back is on pure coding. The SciCode benchmark measures scientific coding ability:
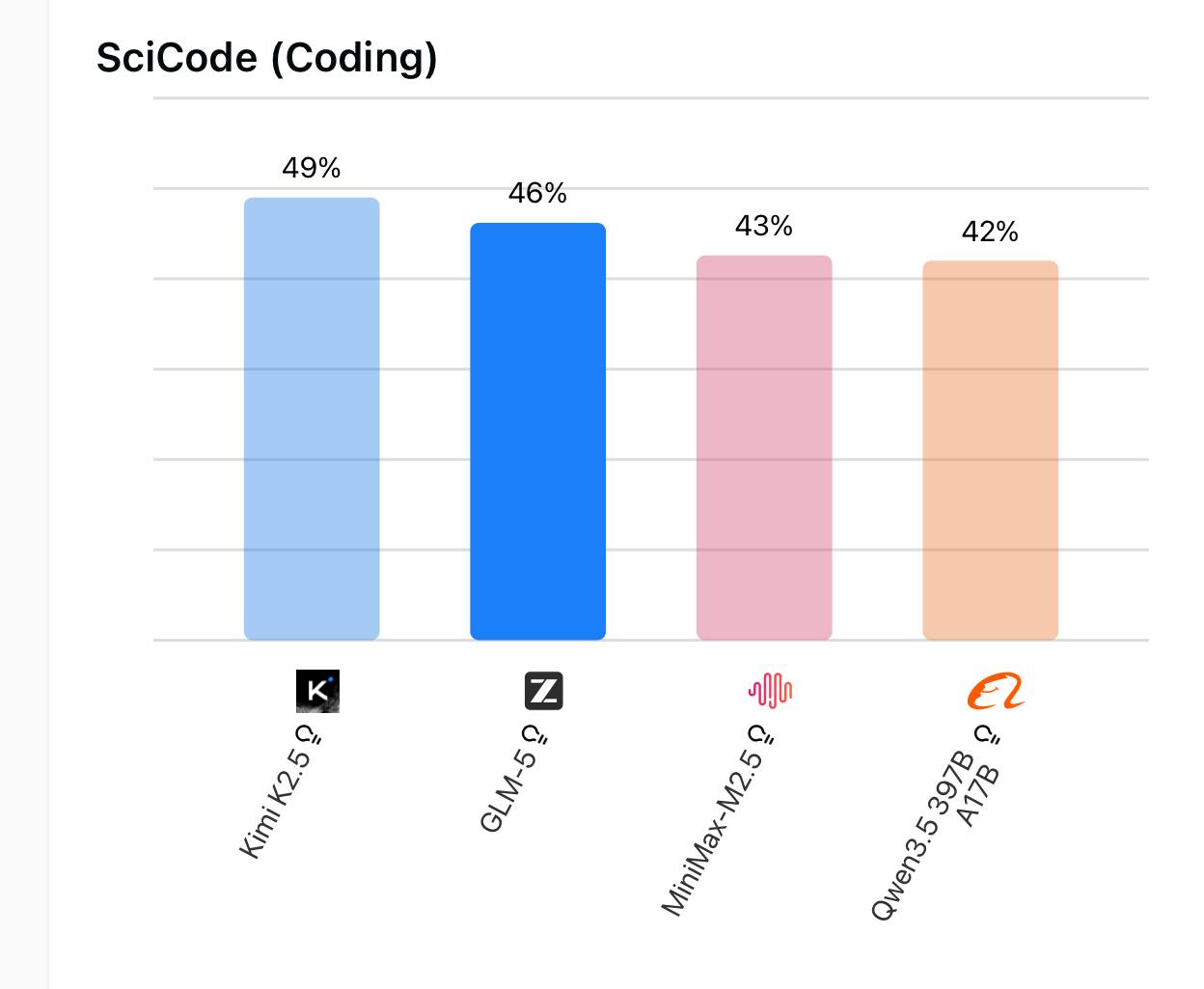 SciCode coding benchmark. Kimi K2.5 edges ahead of GLM-5 on pure coding tasks.
SciCode coding benchmark. Kimi K2.5 edges ahead of GLM-5 on pure coding tasks.
Kimi K2.5 takes the top spot here at 49%, with GLM-5 at 46% and the field tighter overall (Qwen and MiniMax at 42-43%). So if your use case is primarily code generation rather than open-ended agentic reasoning, Kimi K2.5 deserves serious consideration.
Note on DeepSeek V3.2 (Reasoning): DeepSeek V3.2 was not included in the original benchmark charts above. On Terminal-Bench Hard it scores 36%, visible in the full leaderboard chart above. GDPval-AA, hallucination rate, and SciCode scores for DeepSeek V3.2 are not covered in these specific charts – refer to Artificial Analysis for current agentic benchmark data.
Update: MiniMax-M2.7 and Kimi K2.5 have since emerged as the top-rated open-weight models for agentic reasoning on Artificial Analysis. See Section 9: MiniMax-M2.7 vs Kimi K2.5 for Agentic Work for a detailed head-to-head comparison, including SWE-Bench, GDPval-AA, BrowseComp, and Kimi’s Agent Swarm architecture.
Section 3: Context Window
Context window matters more than people often acknowledge. Larger windows mean you can feed in more code, longer documents, or more conversation history without truncation.
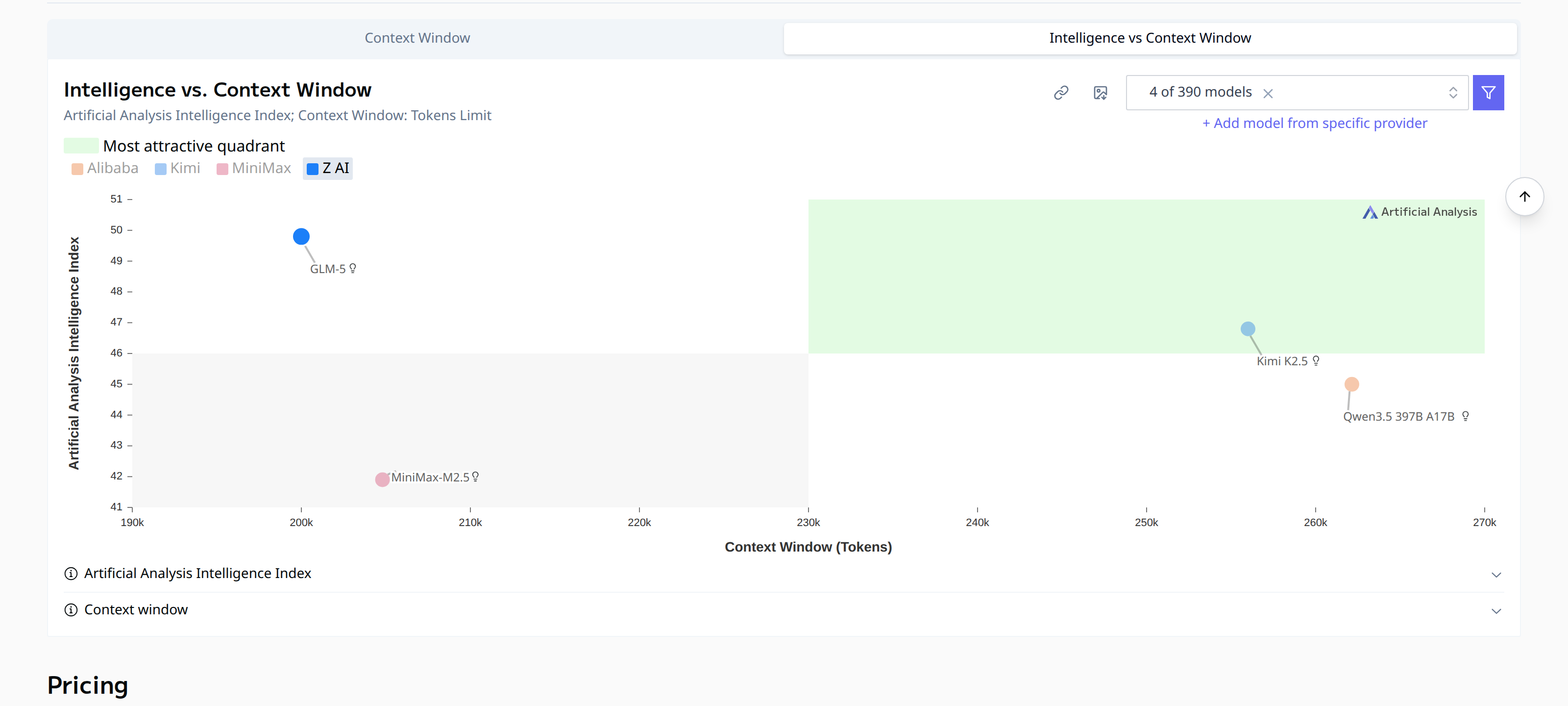 Intelligence vs. context window size. Kimi K2.5 and Qwen3.5 offer significantly larger windows than GLM-5. (Artificial Analysis)
Intelligence vs. context window size. Kimi K2.5 and Qwen3.5 offer significantly larger windows than GLM-5. (Artificial Analysis)
Kimi K2.5 and Qwen3.5 397B A17B both sit at around 260k tokens, a bit ahead of GLM-5’s roughly 200k. If you are doing long-document analysis or extended code reviews, that gap matters. GLM-5’s smaller window is the clearest practical limitation in this comparison.
Note on DeepSeek V3.2 (Reasoning): Not shown in the chart above. DeepSeek V3.2 has a 128k context window – the smallest of all five models in this post. For long-context use cases it is at a clear disadvantage.
Section 4: Output Speed
None of this matters if the model is too slow to use interactively. GLM-5 wins here, and the gap with Kimi K2.5 is significant.
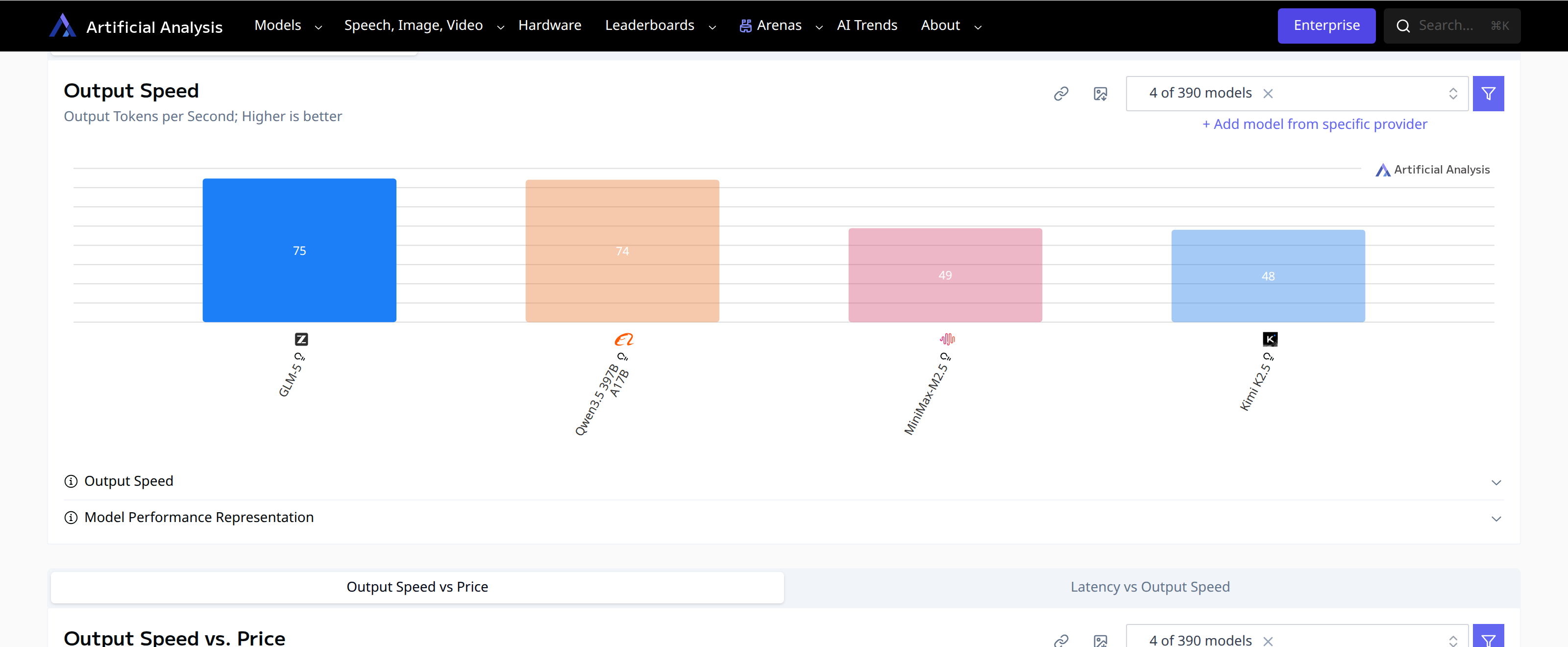 Output speed in tokens per second. GLM-5 and Qwen3.5 lead; Kimi K2.5 lags significantly. (Artificial Analysis)
Output speed in tokens per second. GLM-5 and Qwen3.5 lead; Kimi K2.5 lags significantly. (Artificial Analysis)
GLM-5 and Qwen3.5 come in around 74-75 tokens per second. MiniMax and Kimi K2.5 drop to around 48-49. For interactive use that difference is noticeable. Kimi K2.5 would still be fine for batch or overnight jobs – tasks you kick off before bed and check in the morning – but for real-time interactive work GLM-5 is considerably snappier.
Note on DeepSeek V3.2 (Reasoning): Not shown in the chart above. Native DeepSeek speed is around 32.9 t/s – the slowest in this comparison on their own infrastructure. However, Fireworks delivers it at 105.8 t/s, which flips the picture entirely and makes it the fastest model in the group on that provider.
Section 5: Multimodality
One area where GLM-5 falls short is multimodality. It is text-only – you cannot feed it images or video, and it will not generate them either. If your workflow involves analyzing screenshots, diagrams, charts, or any kind of visual content, GLM-5 is out.
The other three models have varying levels of support:
| Model | Input | Output |
|---|---|---|
| GLM-5 | Text only | Text |
| MiniMax-M2.5 | Text only | Text |
| DeepSeek V3.2 | Text only | Text |
| Qwen3.5 397B A17B | Text + Image | Text |
| Kimi K2.5 | Text + Image + Video | Text |
Kimi K2.5 is the most capable here by a clear margin – it accepts text, images, and video as inputs. It is the only model in this group that can handle video, making it the natural choice for any workflow that involves visual content beyond static images.
Qwen3.5 397B A17B supports image input alongside text, which covers a large share of real-world use cases – screenshots, diagrams, charts, scanned documents. It cannot handle video, but for most developer and research workflows that is not a blocking issue. Given that Qwen3.5 also has the largest context window (262k tokens) and fast output speed, it is a reasonable pick if image understanding matters but video does not.
MiniMax-M2.5 is text-only, which is surprising given that it is a February 2026 release. At a price point of $0.30/$1.20 per million tokens it is the cheapest model in this comparison, and its text-only limitation may simply reflect a deliberate trade-off to keep costs and latency down.
GLM-5 being text-only is arguably the sharpest limitation in its otherwise strong profile. It leads on intelligence, agentic reliability, and speed – but if your pipeline ever needs to process an image or a video frame, you cannot use it without a separate vision model upstream.
DeepSeek V3.2 is also text-only. This matters because it otherwise has strong raw intelligence. For vision-free workflows it is competitive; for anything involving images or video it is not an option without a separate model upstream.
Update: This multimodal advantage becomes even more significant in agentic contexts. Kimi K2.5’s vision capabilities let it “see” screenshots and UI layouts during autonomous task execution, while MiniMax-M2.7 remains text-only. See Section 9 for more.
The bottom line: if multimodality matters for your use case, Kimi K2.5 is the only complete answer. If static image support is enough, Qwen3.5 is a solid alternative with better speed. If your workflow is purely text, GLM-5, DeepSeek V3.2, and MiniMax all have their respective advantages.
Section 6: Cost and Providers
The token prices tell the headline story clearly. All models below are reasoning/thinking variants – the open source models are reasoning-only, and Anthropic prices Claude Sonnet and Opus identically whether you use the non-reasoning or the adaptive reasoning (max) variant. The thinking tokens still cost the same per token; the difference is how many get generated.
| Model | Input (per 1M) | Output (per 1M) |
|---|---|---|
| DeepSeek V3.2 (Reasoning) | $0.28 | $0.42 |
| MiniMax-M2.5 (Reasoning) | $0.30 | $1.20 |
| Kimi K2.5 (Reasoning) | $0.60 | $3.00 |
| Qwen3.5 397B A17B (Reasoning) | $0.60 | $3.60 |
| GLM-5 (Reasoning) | $1.00 | $3.20 |
| Claude Sonnet 4.6 (non-reasoning or max) | $3.00 | $15.00 |
| Claude Opus 4.6 (non-reasoning or max) | $5.00 | $25.00 |
Open source models are 3-5x cheaper on input and 4-8x cheaper on output at face value. But there is an important caveat: GLM-5 and Kimi K2.5 are reasoning models that think through problems via internal chain-of-thought. They generate a lot of tokens you pay for but never see. Kimi K2.5 used 89M output tokens to complete Artificial Analysis’s benchmark suite; Claude Sonnet 4.6 used 14M. Despite that 6x verbosity gap, the total benchmark cost was still $371 for Kimi vs $1,397 for Sonnet – primarily because input tokens are where the big savings are. The short version: how much you save depends on your workload. Input-heavy tasks (RAG, long-context analysis) favor open source 3-4x. Balanced coding or agentic work is more like 2-3x. Pure generation tasks where output dominates the bill narrow the gap considerably, though this comparison is against Sonnet’s non-reasoning variant – with extended thinking on, Claude’s verbosity rises sharply too.
Providers
All five models are available on standard Western inference providers – no Chinese accounts required. DeepInfra is the best single pick for both GLM-5 (~$1.24 blended, 126 t/s) and Kimi K2.5 (~$0.90 blended). Together.ai and Fireworks are solid alternatives for most models. For DeepSeek V3.2 (Reasoning) specifically, Fireworks is the top pick for speed (105.8 t/s) and Novita is the cheapest (~$0.30 blended). All models are MIT or Apache 2.0 licensed and can be self-hosted if you have the hardware.
Prompt caching
Both Claude and open source providers support prompt caching, which cuts the cost of repeated prefixes (long system prompts, tool lists, shared document context). Claude’s caching is explicit – you mark breakpoints and pay $0.30/M for cache reads instead of $3.00/M on Sonnet (a 90% discount). Open source providers like Fireworks apply prefix caching automatically at 50% off, with no markers needed; DeepInfra and Together.ai have similar automatic caching baked in.
The key nuance: caching only applies to input tokens. Output tokens are never cached. With extended thinking enabled on Claude, the model generates a large internal reasoning trace billed at the full $15-$25/M output rate, and caching does nothing for that. The open source reasoning models have the same verbosity, but at $3/M the exposure is far smaller. Caching is most valuable for applications with large, reused system prompts or growing conversation history. It is much less relevant for one-off tasks or highly dynamic prompts.
Most practical starting point
Kimi K2.5 via DeepInfra or Together.ai – cheaper than GLM-5, multimodal, large context, available on familiar providers. For pure text workloads that demand the highest intelligence and reliability, GLM-5 via DeepInfra is the pick.
Summary
Performance
| Model | Intelligence | Agentic (Terminal-Bench) | Hallucination | Coding (SciCode) |
|---|---|---|---|---|
| GLM-5 | 42 (top tier) | Best (43%) | Best (66%) | 2nd (46%) |
| DeepSeek V3.2 | 42 (top tier) | 36% | N/A† | N/A† |
| Kimi K2.5 | Competitive | 2nd (41%) | 2nd (35%) | Best (49%) |
| Qwen3.5 397B | 3rd | 3rd (35%) | Poor (11%) | 3rd (42%) |
| MiniMax-M2.5 | 4th | 3rd (35%) | Poor (11%) | 3rd (43%) |
†DeepSeek V3.2 was not included in the hallucination and SciCode charts used in this post. See Artificial Analysis for current scores.
Practical specs
| Model | Context | Speed | Multimodal |
|---|---|---|---|
| GLM-5 | 200k | 75 t/s | Text only |
| Kimi K2.5 | 256k | 48 t/s | Text + Image + Video |
| Qwen3.5 397B | 262k | 74 t/s | Text + Image |
| MiniMax-M2.5 | 205k | 49 t/s | Text only |
| DeepSeek V3.2 | 128k | 33 t/s (native) / 106 t/s (Fireworks) | Text only |
Cost (per 1M tokens)
| Model | Input | Output | Cache read | Cache write | Verbosity |
|---|---|---|---|---|---|
| DeepSeek V3.2 | $0.28 | $0.42 | varies by provider | varies by provider | High (61M tokens) |
| MiniMax-M2.5 | $0.30 | $1.20 | varies by provider | varies by provider | Moderate (56M tokens) |
| Kimi K2.5 | $0.60 | $3.00 | varies by provider | varies by provider | High (89M tokens) |
| Qwen3.5 397B | $0.60 | $3.60 | varies by provider | varies by provider | High (86M tokens) |
| GLM-5 | $1.00 | $3.20 | varies by provider | varies by provider | Very high (110M tokens) |
| Claude Sonnet 4.6 | $3.00 | $15.00 | $0.30 (-90%) | $3.75 (+25%) | 14M (non-reasoning) / N/A (max)† |
| Claude Opus 4.6 | $5.00 | $25.00 | $0.50 (-90%) | $6.25 (+25%) | 11M (non-reasoning) / N/A (max)† |
†The “max” (adaptive reasoning) variants show N/A verbosity because token counts vary per task depending on how much thinking is triggered. With full extended thinking, Claude’s output token counts can match or exceed the open source reasoning models – at $15-$25/M rather than $3-$3.20/M. Caching helps on input but does nothing for those thinking tokens, which is where the cost gap is hardest for Claude to close.
For most agentic or assistant use cases: GLM-5. Best intelligence, best reliability, fastest response. The smaller context window and slightly higher verbosity cost are the tradeoffs.
For coding-heavy workloads where speed is less critical, or if you need multimodal input (images, video): Kimi K2.5. It beats GLM-5 on SciCode, nearly matches it on terminal coding, has a bigger context window, and is the only one of these four that handles visual inputs.
The analogy I keep coming back to: GLM-5 is the Claude Opus of the open source world – the highest-capability option, the one you reach for when the task demands the most. Kimi K2.5 is the Sonnet – fast, versatile, and covers more ground. The catch is that GLM-5’s lack of vision support is a serious handicap. In practice that probably means running them together: GLM-5 as the primary model and Kimi K2.5 as the fallback or helper whenever a task involves images or video.
DeepSeek V3.2 (Reasoning) makes the most sense when cost is the overriding constraint and your workload is text-only with modest context requirements – at $0.28/$0.42 per million tokens it is in a different pricing tier from everything else, and its intelligence score matches GLM-5. If your pipeline stays under 128k tokens per call and never touches images, it is hard to argue against.
I am still evaluating whether to actually run these for any of my own workflows. I still have a Claude Max subscription, and for me capability trumps everything. If Claude did not have an actual max subscription tier, I would probably be primarily using some combination of GLM-5 and Kimi K2.5 – the price point is that attractive.
Section 9: Update (March 2026): MiniMax-M2.7 vs Kimi K2.5
On ArtificialAnalysis.ai, as of March 2026, MiniMax-M2.7 and Kimi K2.5 are the top-rated open-weight models for agentic reasoning. While MiniMax leads in overall intelligence and cost-efficiency, Kimi K2.5 is currently considered the superior “autonomous agent” due to its unique orchestration features.
Benchmark Comparison
| Metric | Kimi K2.5 (Reasoning) | MiniMax-M2.7 |
|---|---|---|
| Intelligence Index (v4.0) | 47 | 50 (Leader) |
| GDPval-AA Elo | 1309 | ~1285 (Estimate) |
| SWE-Bench Verified | 76.8% | 80.2% |
| BrowseComp (Web Research) | 78.4% (with Swarm) | 76.3% |
| Tau2Bench (Tool Use) | ~79% | 80.2% |
| HLE (Humanity’s Last Exam) | 50.2% | 46.8% |
1. GDPval-AA and Real-World Agency
GDPval-AA measures a model’s ability to perform economically valuable tasks (like building a presentation or financial analysis) using shell and web access.
Kimi K2.5 holds a slight edge here with a confirmed Elo of 1309. It is currently the top open-weight model on this specific leaderboard, trailing only the newest GPT and Claude frontier models.
MiniMax-M2.7 performs exceptionally well in technical accuracy but is slightly less “proactive” in correcting its own errors in long-horizon loops compared to Kimi.
2. The “Agent Swarm” Factor
The biggest differentiator for agentic tasks is Kimi’s Self-Directed Agent Swarm.
Kimi K2.5 can orchestrate up to 100 sub-agents to parallelize tasks. On the BrowseComp benchmark, this allows it to jump from 60.6% to 78.4% efficiency by having multiple “agents” search different parts of the web simultaneously.
MiniMax-M2.7 relies on a single-agent reasoning loop. While its core logic is more robust (scoring higher on the general Intelligence Index), it lacks Kimi’s native parallel execution framework.
3. Engineering and Coding (SWE-Bench)
MiniMax-M2.7 is the winner for pure software engineering. It scores over 80% on SWE-Bench Verified, making it one of the few open models that can genuinely compete with Claude 4.5/4.6 for autonomous repository editing.
Kimi K2.5 is strong (76.8%) but is often noted for being overly verbose, sometimes generating “over-engineered” solutions that require a second pass to simplify.
4. Multimodality and Context
Kimi K2.5 is natively multimodal. It can “see” screenshots, UI layouts, and diagrams to inform its agentic decisions. For any task involving a GUI or visual document analysis, Kimi is the clear choice.
MiniMax-M2.7 remains text-only, which limits its agency in workflows that require interacting with visual interfaces.
Final Verdict
Use MiniMax-M2.7 for software engineering and backend automation. It has higher pure intelligence (50 vs 47) and is nearly half the price, making it more efficient for high-volume coding agents.
Use Kimi K2.5 for complex web research and visual tasks. Its 1309 GDPval-AA score and “Agent Swarm” make it the most “human-like” in how it manages multi-step, multi-source projects.
Appendix: OpenRouter vs Direct Providers
OpenRouter is a proxy that exposes a single OpenAI-compatible API across dozens of inference providers. One key, one integration, automatic fallback if a provider goes down, and unified billing across everything.
As of March 2026, GLM-5 and Kimi K2.5 are not yet on OpenRouter, so direct is the only option for those two. MiniMax-M2.5, Qwen3.5, and DeepSeek V3.2 are available there.
Use OpenRouter when you are prototyping, want to switch models without code changes, or want automatic failover and consolidated billing at low to medium volume.
Use a direct provider when caching hit rates matter (OpenRouter’s load balancing across providers kills cache locality), you need provider-specific features (dedicated deployments, fine-tuning, SLAs), or the model is not yet on OpenRouter. Note: OpenRouter does not add a per-token markup – provider pricing passes through exactly; they only charge a small fee on credit purchases.
Does OpenRouter support modality-based failover? No – failover triggers on provider availability failures, not capability mismatches. Sending an image to a text-only model will not automatically reroute to a vision-capable one; you need to handle that in your application layer.
Does OpenRouter support prompt caching? It passes through caching to the underlying provider (e.g. Anthropic’s cache_control markers work), but OpenRouter’s default load balancing spreads requests across multiple providers, killing cache hit rates. To make caching reliable, pin to a single provider using the provider.order request parameter.